Time to read: 6 min read
Drag&Drop Startpage with mostly JavaScript
# Motivation
First thing we learnt to do with html in high school was a startpage with a list of links. Some of my friends are still using that system to this day. They either host it on some free domain, or they run it from the computer's file system.
I myself have been wanting to take a spin on this exercise for a long time, but I lacked the right idea, until I discovered that drag&drop is actually humanly possible to implement in vanilla.js (opens new window). I've never done this before, but drag&drop functionality would be awesome, because it would make it super easy to update and change the underlying list of links. I realized I would love to learn how to do that, while I also saw it as the one feature that would make me comfortable enough to not abandon using the site.
Of course there's many cool frameworks ready to do the heavy lifting, but I wanted my startpage to be opened from the file system instead of having to host it. This way I could have a simple html file and a single database file. It would be fast to load, easy to share with friends who know a bit of html, and I would retain the maximum level of ownership. I can switch between browsers, and keep everything as is. No registration required, no invisible magic going on under the hood, no cloud hosting or setup required. It would work even if there is no internet connection, which doesn't make sense, because without internet I can't open the links anyway, but hey.
# Product
# Features
The code can be viewed in this repository (opens new window)
# Initialization
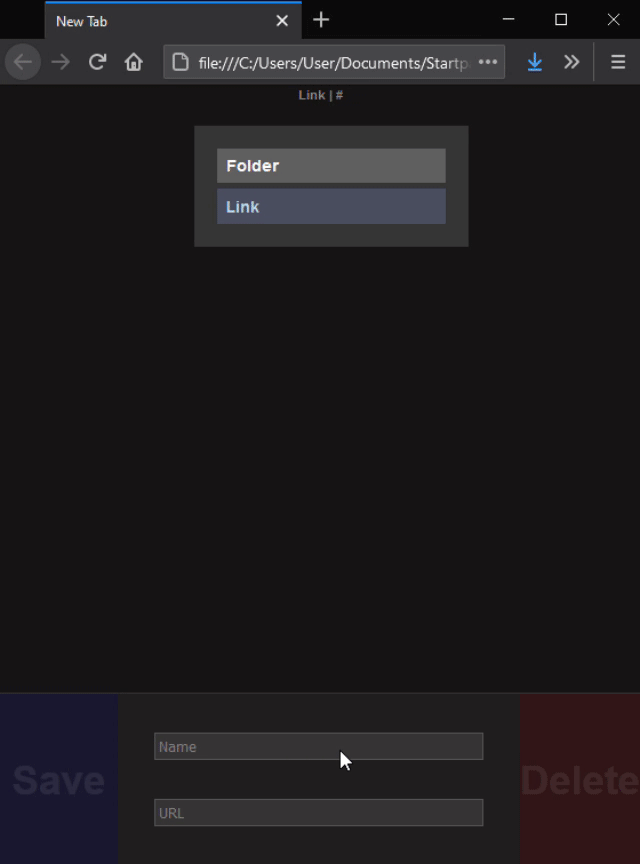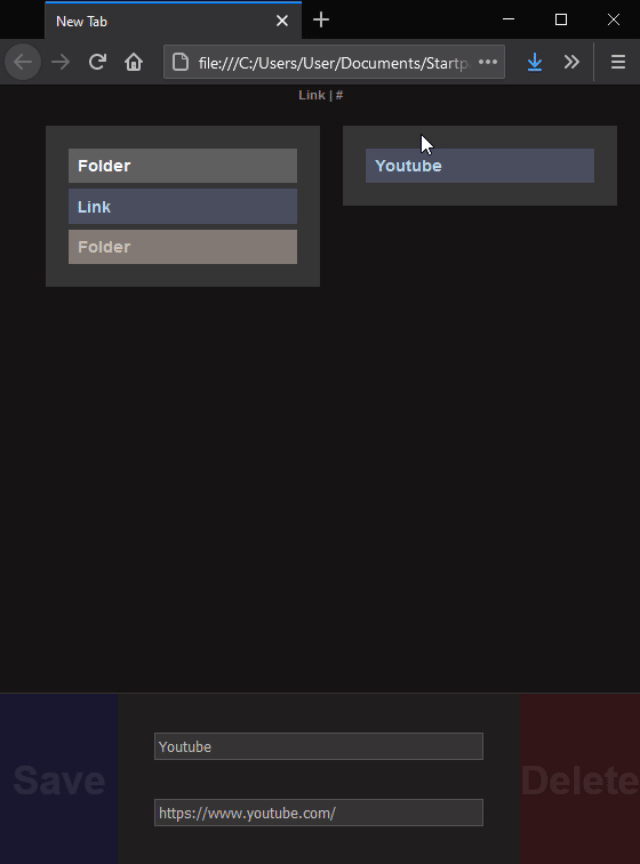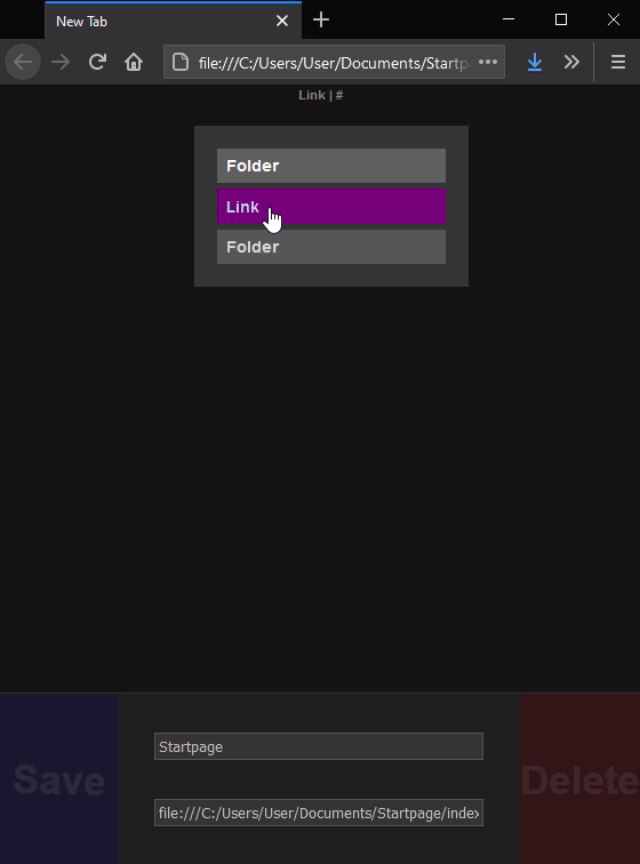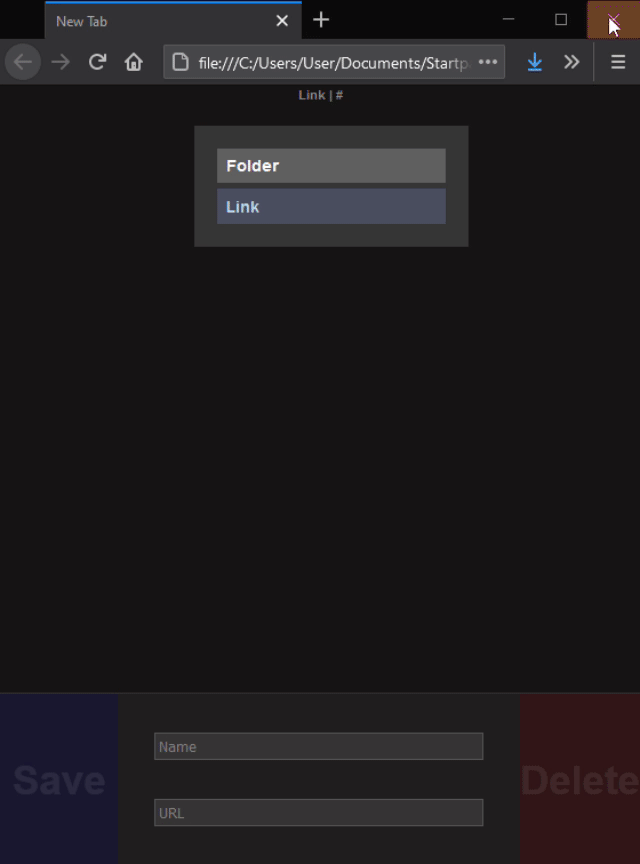
Every link and folder has an id, and a parent folder they belong to. At initialization, the zeroth folder always gets generated and displayed, paving the way for the database to get read and placed inside it nicely. If no database is to be found, an example one will show with one folder and one link.
# Add new element
A link basically just needs a name to click on, and a URL. So I thought, if no URL is provided, then make the object a folder instead. Just drag the bottom element wherever you want to place it and you're done.
What also works is dropping either an existing element on the bottom input bar, or dropping a website itself as we're used to when quickly saving bookmarks. The link contained in the dropped element will fill the URL input field, and if it was an element from the startpage, or a folder, then the Name filed will populate too. This is currently the only way to edit links: extract them this way, rewrite it, and dropping it back. The original has to be deleted manually. I'm not entirely sure how the editing process could be made easier, but I rarely need to do that, and sometimes I just edit the json file directly. It would be nice to have a shift-click or similar function to edit an element, maybe.
# Delete element
To delete a link, it just has to be dropped on the Delete button in the bottom right corner. A popup will ask whether we're sure, and if we are, it will happen. If a folder is deleted, every single element contained within it will get deleted too.
# Save changes
Right now the way I handle the database is it's basically a JavaScript file that simply declares a json variable. At the beginning of the html file it is imported, and thus the json data can be handled.
Whenever the structure changes, it is the user's duty to "save" changes, which consists of generating a new JavaScript file and offering it for download. I realize this is not ideal, as it could be automated. The bottleneck is that normally, browsers handle JavaScript in a sandbox, and don't give it access to the file system. In this perspective, user interaction in form of downloading and saving a file is required. I researched a little bit more though, and found out about localStorage (opens new window), where the browser can be asked automatically to save and remember data. This would obviously not work across browsers, but within one it would work more seamlessly. Perhaps one day I'll look into it more.
When the json data structure is being assembled, there's a check that looks whether every element does have any existing parent at all. Unreachable branches in the tree should not need to be saved, so they get deleted. This should theoretically not be a scenario, because children of deleted folders get deleted too, but I thought it makes sense to prepare to keep the data clean. Perhaps a few safety features would be warranted, as there currently is no alert to the user whether items have been deleted this way.
# Little Extra
The bigger and deeper the database gets, the more likely I'll start to forget what I even put in there. To help me remember all the things I saved, I display a random link on top of the site. When it's something I don't remember, I open it to check it out. By the way, clicking with the middle mouse button opens link on a new tab right away without changing tabs, and clicking on tabs with the middle mouse button closes them. Ctrl+W will close the current tab. Knowing this I always set up my browser to not display the "close" button on the tab, so there's more real estate left for useful info, namely titles of the websites.
# Caution
As of right now, dragging folders inside of them is permitted, but clearly shouldn't be. Also, when changes are made, the little "save" icon shakes a little, but it would be better if closing the tab (or the browser) would prompt an alert about unsaved changes.
Also I would say it makes sense to some times save a copy of the json file, or to save it in a Dropbox folder with version history or something like that, as I haven't tested the site in any professional way. I tested it manually in whichever ways I came up with, but it's better to be cautious.